Shapley and SHAP: State-of-the-Art Tools for Model Interpretability
Shapley Value 来自博弈论的公平分配
Shapley 值通过假设实例的每个特征值是游戏中的 “玩家” 来解释预测,其中预测目标是总⽀出。Shapley 值是联盟博弈论的⼀种⽅法,它将告诉我们如何在特征之间公平地分配总⽀出。我们要通过一个简单的例子,来从理论上理解 Shapley Value,方便将其应用到所需的领域。
假定已经训练了机器学习模型来预测公寓价格。对于某套公寓,它的预计价格为 300,000 欧元,需要对此做出解释。公寓的⼤⼩为 50 平⽅⽶,位于 2 楼,附近有公园,并且禁⽌猫⼊内,所有公寓的平均预测价格为 310,000 欧元。与平均预测相⽐,每个特征值对预测有多少贡献?
我们作下面的类比
- “游戏” 是数据集单个实例的预测任务
- “收益” 是此实例的实际预测值减去所有实例的平均预测值
- “玩家” 是实例的特征值
我们想用玩家来解释收益的问题,也就是用特征值来解释这-10000的差值
Shapley 值的数学定义:合作博弈模型
在博弈论中,一个合作博弈由两个元素定义:。
玩家集合 ():参与游戏的所有玩家。在你的例子中,玩家就是特征。为了推导清晰,我们假设这套公寓只有 3 个特征:
玩家 1:公园附近 (Park)
玩家 2:禁止猫 (No Cats)
玩家 3:50平米 (Area)
所以,玩家总数 ,集合 。
特征函数 ():也叫价值函数,表示任意一个玩家子集(联盟 )所能获得的收益。
- 在机器学习中, 定义为:在只知道子集 中特征值的情况下,模型对房价的期望预测值。
- :没有任何特征时的预测值,也就是所有公寓的平均价格(310,000 欧元)。
- :拥有所有特征时的最终预测值(300,000 欧元)。
问题:我们总共产生了 欧元的“差价”(总收益)。这 -10,000 欧元,应该如何精确、无争议地分配给玩家 1、2 和 3?
Shapley 博士在 1953 年给出的解答,也就是第 个玩家(特征)的 Shapley 值 的精确公式如下:
- :表示所有不包含玩家 的联盟(子集)。
- :这就是玩家 加入联盟 后带来的边际贡献 (Marginal Contribution)。
- :这是一个权重系数。它的组合数学意义是:在所有 种可能的玩家加入顺序中,玩家 刚好在子集 的玩家全部加入之后,紧接着加入的排列数占比。
用一句话概括:Shapley 值是所有可能的联盟 (Coalition) 中特征值的平均边际贡献。
结合买房例子的精确计算推导
现在,我们要计算“禁止猫”(玩家 2)的 Shapley 值 。
已知 ,我们需要穷举所有不包含玩家 2 的联盟 ,它们是:(空集)、、、。
假设我们通过对数据集进行条件期望计算,得到了以下各个联盟的 预测值(单位:万欧元):
- (只知道有公园)
- (只知道50平米)
- (知道有公园且50平米)
- (只知道禁止猫)
- (公园 + 禁止猫)
- (禁止猫 + 50平米)
- (全部特征集齐,即最终预测)
按照公式,我们将计算四个子项的加权求和:
1. 当 (没有任何特征存在时,玩家 2 加入):
- 权重:
- 边际贡献:
- 加权结果:
2. 当 (公园特征已存在,玩家 2 加入):
- 权重:
- 边际贡献:
- 加权结果:
3. 当 (50平米特征已存在,玩家 2 加入):
- 权重:
- 边际贡献:
- 加权结果:
4. 当 (公园和50平米特征都存在,玩家 2 加入):
- 权重:
- 边际贡献:
- 加权结果:
最终计算 :
结论:“禁止猫”这个特征,严格地让这套房子的预测价格下降了 11,670 欧元。
Shapley Value 的价值
你可能会问:为什么要用这样的权重去算?直接把特征剔除掉算一次差值不就行了吗?(也就是类似置换特征重要性的思想,这种想法不够完美)
这就是 Shapley 值在可解释性领域被奉为圭臬的原因。它是唯一同时满足以下四个博弈论公理的分配方法
有效性 (Efficiency / 可加性):
所有特征的 Shapley 值之和,必须精准等于最终预测值与基础值的差。没有任何多余,也没有任何遗漏。
对称性 (Symmetry):
如果两个特征在所有可能的联盟中,产生的边际贡献完全一样,那么它们的 Shapley 值必须完全相等。这保证了算法不带有针对某些特征的偏见。
虚拟性 (Dummy Axiom / 零玩家):
如果一个特征(比如买房送的毫无价值的赠品)加入任何联盟都不能改变预测值,即边际贡献永远为 0,那么它的 Shapley 值必须为 0。
线性组合 (Additivity):
如果我们用模型 A 和模型 B 分别预测房价,并将两者的结果相加作为新模型 C 的预测值。那么某个特征在模型 C 中的 Shapley 值,必然等于它在 A 和 B 中 Shapley 值的简单相加。
它解决的问题是:面对包含深度非线性和特征交互的机器学习模型,传统的置换特征重要性(Permutation Importance)难以处理特征间的依赖和耦合效应。Shapley 值通过穷举所有特征可能的“出场顺序”并取期望,给出了一种在博弈论公理约束下更公平的归因方式。
应用示例
特征值 的 Shapley 值的解释是:与数据集的平均预测相⽐,第 个特征的值对这个特定实例的预测的贡献为 Shapley 值同时适⽤于分类 (输出结果是概率) 和回归问题。
我们用宫颈癌的危险因素分类数据集进行举例
宫颈癌数据集中⼀名⼥性的 Shapley 值。预测为 0.57,也就是比平均概率大 0.54
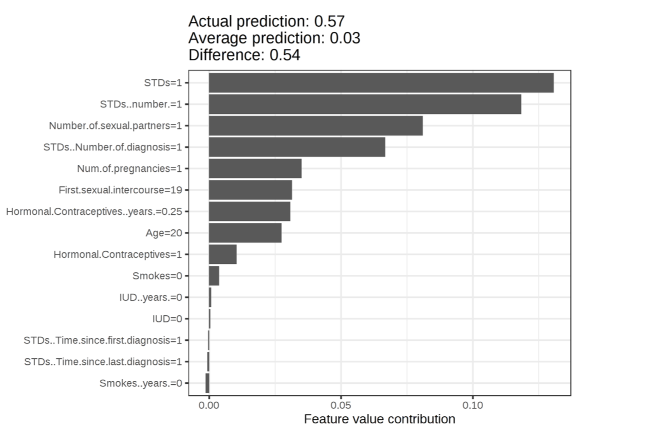 能看出,就这个例子而言 STDs 的影响是最大的 并且是增大概率的影响
能看出,就这个例子而言 STDs 的影响是最大的 并且是增大概率的影响
Shapley 可以实现对比的精确解释
Shapley 值允许进⾏对比性解释。⽆需将预测与整个数据集的平均预测进⾏⽐较,你可以将其与⼦集甚⾄单个数据点进⾏⽐较。这引入了在实际应用中经常被初学者忽略的特性:解释的相对性(Relativity of Explanation)。
在人类的认知习惯中,当我们问“为什么”的时候,我们实际上是在问“为什么是 A 而不是 B?”。这就叫做对比性解释(Contrastive Explanation)。我们需要回到上一讲中提到的特征函数 以及基础值 。
改变背景分布(Background Distribution)
在上一节的精确推导中,我们设定 欧元。这个 31 万是怎么来的?它是在我们“什么特征都不知道”的情况下,模型对整个数据集所有公寓预测价格的平均值。
在计算包含部分特征的联盟价值 时(例如,只知道“公园附近”),那些“不知道”的特征(例如“面积”和“是否允许养猫”),在数学上是如何处理的?
标准的做法是:**用整个数据集里其他公寓的特征值去填补(边缘化处理),然后求期望。**因此这句话的实际含义是:你可以替换这个“用来填补和计算平均值的背景数据集”,从而改变解释的基准(Baseline)。
让我们用公寓例子,演练这三种对比级别:
与“整个数据集”对比(默认标准情况)
- 背景数据:整个城市的 10 万套公寓。
- 基础值 :全城平均房价 31 万。
- 你要解释的问题:“为什么这套公寓(30万)比全城平均水平便宜了 1 万?”
- Shapley 值的含义:禁止猫(-1.167万),公园附近(+0.5万)等,是相对于全城平均水平的贡献。
与“特定子集”对比(对比性解释 - 子集)
假设你想向一位专门看老城区的客户解释房价。全城的平均价对他没有意义。
- 背景数据:你只把“老城区”的 5000 套公寓作为背景数据集输入给模型。
- 基础值 :老城区的平均房价,假设是 35 万。
- 你要解释的问题:“为什么这套公寓(30万)比老城区的平均水平便宜了 5 万?”
- Shapley 值的含义:此时重新计算的 Shapley 值会发生剧变。因为老城区可能普遍没有公园,此时“公园附近”这个特征带来的正向贡献 会比之前大得多,而它填补了与老城区均价之间那 5 万差额的一部分。
与“单个数据点”对比(对比性解释 - 个体)
这是最极端的对比。客户指着街对面的另一套公寓(卖 32 万)问你:“这两套房面积一样,地段一样,为什么我这套只值 30 万?”
- 背景数据:仅仅只用街对面那套“32万的公寓”作为唯一的背景数据。
- 基础值 :就是那套对比公寓的预测值(32万)。
- 你要解释的问题:“为什么这套公寓(30万)比街对面那套公寓便宜了 2 万?”
- Shapley 值的含义:在这种情况下,所有相同的特征(面积、地段)的 Shapley 值会直接变成 0(因为它们在两个样本之间没有差异,边际贡献为0)。最终的差额(-2万)会 100% 完美地分配给那些不同的特征(比如,对面允许养猫,而这套禁止猫)。
注意,对比性解释不意味着要重新训练模型。模型仍在整个数据集上训练;追求 Shapley 带来的解释性时,我们更换的是背景数据的基准,从而改变解释基准。
这种对比在真实业务中很有用。自定义对比基准的能力,也是 LIME 等方法较难稳定做到的。
- 客诉排查:“为什么用户 A 的信用评分比用户 B 低了 50 分?”(单个数据点对比)
- 人群差异分析:“为什么这个月的流失用户的流失概率,比上个月的活跃用户高出 20%?”(子集对比)
- 模型 Debug:“为什么这个被误判为正类的负样本,其得分比真实的负样本群体高这么多?”(子集对比)
通过改变 SHAP 计算时传入的 background_data 参数(Python 扩展),我们可以让模型解释从泛泛而谈变成精准打击。Shapley 带来的优秀可解释性,是当之无愧的最优秀手法之一。
优点与缺点
通过上面的推导可以看到,计算 Shapley 值的计算复杂度是 。如果模型有 100 个特征,就算动用全球最顶尖的超算,在宇宙毁灭前也算不完一次预测的精确值。这也是纯理论的 Shapley 值在机器学习中“无法进行广泛应用”的原因,直到 SHAP 技术出现。
Shapley 值可能会被误解。特征值的 Shapley 值不是从模型训练中删除特征后的预测值之差。Shapley 值的解释是:给定当前的⼀组特征值,特征值对实际预测值与平均预测值之差的贡献就是估计的 Shapley 值。
使⽤ Shapley 值⽅法创建的解释始终使用所有特征。对于寻求稀疏解释的人来说并不合适
Shapley 值为每个特征返回⼀个简单值,但没有像 LIME 这样的预测模型
SHAP —— 变得更快,变得可用
从理论完美的 Shapley 值走向工程实用的 SHAP(SHapley Additive exPlanations),是机器学习可解释性领域的一次跨越。要理解 SHAP,不能只把它看作一个 Python 库。更需要追问的是:Lundberg 和 Lee 在 2017 年提出 SHAP 时,到底解决了 Shapley 值的哪些缺陷?又妥协了什么?
维度灾难与近似计算
我们在上一节推导过,计算精确的 Shapley 值需要遍历所有可能的特征组合,时间复杂度是 。对于一个有 100 个特征的模型,哪怕计算一个样本都需要恐怖的时间,完全不现实。
SHAP 是如何解决的? SHAP 并没有发明新的分配理论,而是巧妙地将 Shapley 值转化为了一个加性特征归因方法 (Additive Feature Attribution Method)。它引入了一个简化的局部解释模型 :
其中 表示特征是否存在的二进制向量(1 表示特征在联盟中,0 表示被隐藏), 就是我们要算的 Shapley 值。
为了求解这个方程,SHAP 提出了两种主要的近似算法:
KernelSHAP (模型无关):
它是一个加权线性回归。它随机抽取一部分联盟 ,并为每个联盟分配一个权重——Shapley Kernel :
通过最小化加权平方损失来拟合线性模型,得到的回归系数 就是近似的 Shapley 值。这直接把 LIME(局部代理模型)和 Shapley 值(合作博弈)在数学上统一了起来。
TreeSHAP (树模型专用):
利用决策树的内部结构(节点的分裂路径和样本覆盖率),将计算复杂度从指数级降到多项式级 ( 为树的数量, 为叶子数, 为深度)。这就是在 XGboost 或 LightGBM 中算 SHAP 会如此之快的原因。
问题好像得到了解决,但这样的近似计算意味着我们一定失去了什么
特征的“缺失”到底意味着什么?(The Missingness Problem)
在博弈论中,玩家缺席很容易理解(他不参加游戏)。但在机器学习中,特征缺席是一个极具争议的数学问题。你的模型一旦训练好,就必须吃进所有的特征,大部分模型不能直接向神经网络输入一个 NaN。
SHAP 面临的抉择与讨论:
为了计算包含部分特征的联盟价值 ,我们需要对不在联盟中的特征(记为 )进行处理。学术界有两种截然不同的路线:
边缘期望 (Marginal Expectation / 介入法):
强制打断特征间的关联,假设已知特征 和未知特征 是独立的。实际操作是用背景数据集(Background Data)里的值去随机替换缺失的特征。
问题:这会导致严重的反事实样本(Out-of-Distribution, OOD)。比如联盟里保留了“怀孕=True”,但用背景数据填补了“性别=男”,模型会被迫对一个完全不符合现实的数据点做出预测。这是 SHAP 至今饱受诟病的地方。
条件期望 (Conditional Expectation / 观察法):
考虑特征间的相关性,用符合已知特征条件的分布去推断未知特征。
问题:它违背了 Shapley 值的“虚拟性公理”。如果模型根本没用到特征 A,但特征 A 和特征 B 强相关,条件分布会把特征 B 的部分功劳错误地归因给特征 A。
目前的现状:标准的 shap 库默认倾向于使用第一种(边缘期望/背景数据替换),因为它更容易计算且符合因果干预的直觉,但这也就引出了下一个致命问题。
特征相关性陷阱 (The Correlation Trap)
这是目前可解释 AI 领域最前沿的研究难题之一,由于边缘期望的方法生成不可靠样本,因此在这个SHAP计算中,会导致最终计算得到的SHAP Value会被扭曲,且仅仅是因为在高维统计中一定会出现的相关性。
举个极端的例子:假设“房屋面积(平米)”和“房屋面积(平方英尺)”被同时扔进了模型。由于它们 100% 正相关,模型实际上只需要其中一个就能做出完美预测。
- 如果使用 TreeSHAP,它可能会在这两个特征上随机分配权重(比如一边 50%)。这会导致原本极其重要的“面积”特征,在 SHAP 概要图中重要性减半,排名暴跌。
- 这会误导业务人员,让他们以为面积不重要。
- 合并高度相关的指标是必要的,但是无法完全解决这个问题。
值得研究的方向:现在学术界正在研究通过计算“不对称 Shapley 值(Asymmetric Shapley Values)”或者结合“因果图(Causal Graphs)”来强制规定特征的解释顺序,从而剥离混杂的共线性干扰。
相关性 vs. 因果性 (Correlation vs. Causation)
这是应用 SHAP 时常见的思想误区,也是因果推断和事后解释的常见误区。
SHAP 解释的是**“模型学到了什么规律”,而不是“真实世界的因果关系是什么”**。
如果你的模型发现“带打火机的人”患肺癌的概率高,SHAP 会诚实地告诉你:“打火机”这个特征对提高患病预测值有极大的正向贡献。
但在业务应用中,如果你据此得出结论:“没收人们的打火机可以降低肺癌发生率”,那就大错特错了。SHAP 只是忠实地反映了模型的偏见和数据中的相关性,它不能替代因果推断(Causal Inference)。
示例
下文关于 SHAP 聚合解释、特征重要性、概要图、依赖图与交互值的组织方式,参考了 Christoph Molnar 在 Interpretable Machine Learning 中的 SHAP 章节。
我们用宫颈癌的危险因素分类数据集举例
由于 SHAP 计算 Shapley 值,因此其解释与 Shapley 值示例⼀节中的解释相同,不过我们有着一些比较有趣的可视化手段 如下
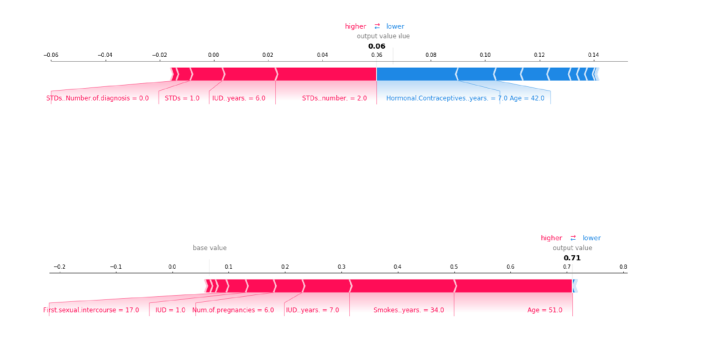 箭头和长度与中线的位置一起体现了SHAP效应
箭头和长度与中线的位置一起体现了SHAP效应
- 第一个例子虽然有STDs增大了概率,但是Age补回了不少
- 第二个例子因为Age等多个因素增大了概率,最后有着很大的概率 这些是对单个预测的解释。
Shapley 值可以合并为全局解释。如果我们为每个实例运⾏ SHAP,则将获得 Shapley 值矩阵。此矩阵每个数据实例具有⼀⾏,每个特征具有⼀列。我们可以通过分析此矩阵中的 Shapley 值来解释整个模型。
SHAP 特征重要性
SHAP 特征重要性背后的想法很直接:具有较⼤ Shapley 绝对值的特征更重要。由于我们需要全局重要性,因此在数据中对每个特征的 Shapley 绝对值取平均值:
我们可以绘制SHAP特征重要性图
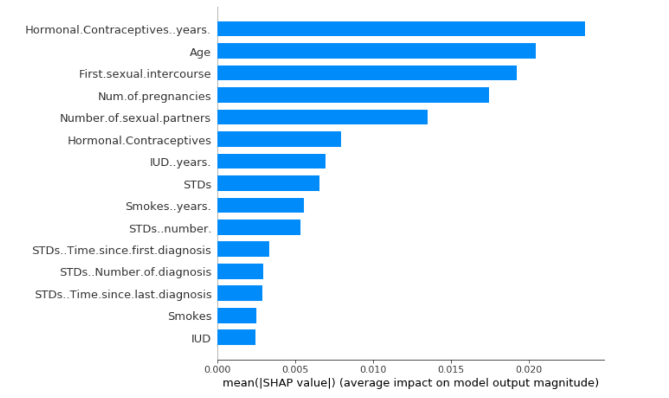
SHAP 特征重要性是置换特征重要性的替代⽅法。两种重要性度量之间存在很⼤差异:置换特征重要性基于模型性能的下降。SHAP 基于特征归因的⼤⼩。
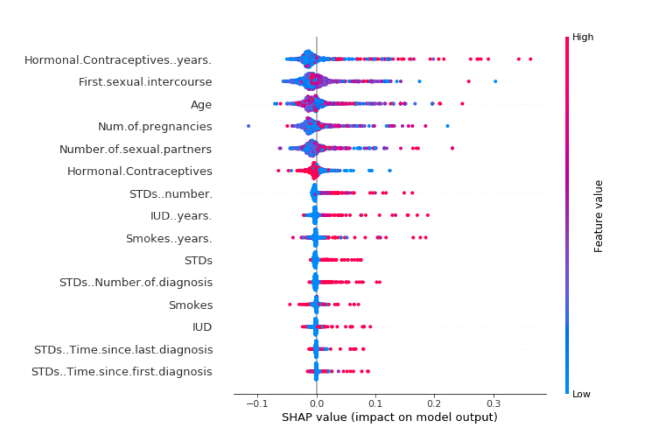
SHAP 概要图
特征重要性图有⽤,但除了重要性之外不包含其他信息。要获得更多信息,需要使用摘要图
概要图将特征重要性与特征效应结合在⼀起。概要图上的每个点都是⼀个特征和⼀个实例的 Shapley 值。y 轴上的位置由特征确定,x 轴上的位置由 Shapley 值确定。这些特征根据其重要性排序。
SHAP依赖图
在概要图中,我们⾸先看到特征值与对预测的影响之间的关系。但要了解这种关系的确切形式,我们必须查看 SHAP 依赖图。
SHAP 特征依赖关系可能是最简单的全局解释图:从数学上说,他只是如下的散点图
如下图所示
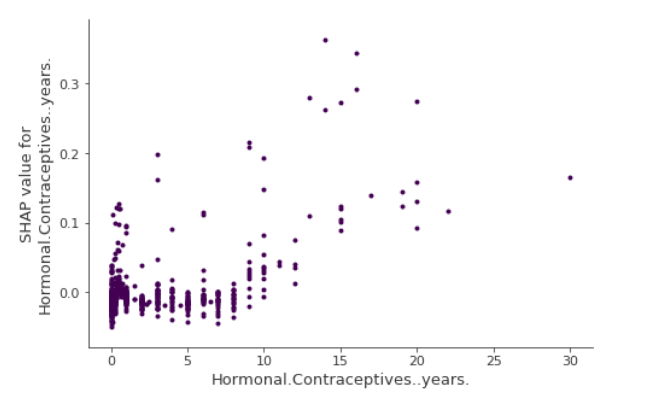 可以看出,HCyears的增加会增大SHAP value;它会明显增加患病概率
可以看出,HCyears的增加会增大SHAP value;它会明显增加患病概率
SHAP 依赖图是部分依赖图和累积局部效应图的替代⽅法,不是对平均而是对全局效应的评估。SHAP在轴上的分散往往暗示交互效应的存在
SHAP 交互值
交互效应是在考虑了单个特征效应之后的附加的组合特征效应。博弈论中的 Shapley 交互指数定义:
考虑了一个交互特征的SHAP依赖图为
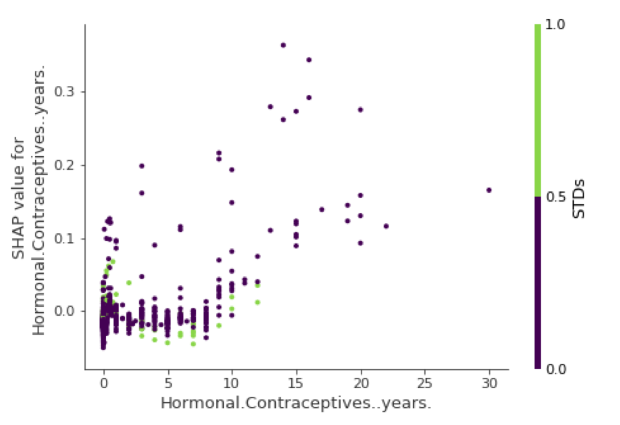 高 STDs 降低了最后的 SHAP value
高 STDs 降低了最后的 SHAP value
SHAP 的深度扩展:神经网络的黑盒破解
处理表格数据时,TreeSHAP 凭借其多项式级别的时间复杂度,解决了以 LightGBM 或 CatBoost 为代表的树模型解释问题。但在实际算法演进中,当我们面对包含稠密与稀疏特征的深度学习架构(如 DeepFM、双塔模型或大型语言模型)时,TreeSHAP 便无能为力,而 KernelSHAP 的计算成本又会随着神经网络深度增加而引发显存爆炸。
为了解决深度学习模型的特征归因,学术界延伸出了两套专用的近似计算框架:
DeepSHAP:基于反向传播的乘子链
DeepSHAP 是对 DeepLIFT(Deep Learning Important FeaTures)算法的 SHAP 适配版。它的思路是:绕开暴力穷举,利用神经网络自带的反向传播(Backpropagation)机制来分配贡献。
- 工作原理:DeepSHAP 需要一个“背景输入(Background Input)”和一个“实际输入(Actual Input)”。数据正向穿过网络时,记录下每个神经元激活值的差值()和输入的差值()。
- 线性近似:对于非线性激活函数(如 ReLU 或 Sigmoid),DeepSHAP 采用线性插值的方式,计算出一个“乘子(Multiplier)” 。
- 链式法则反推:从输出层开始,利用修正后的链式法则,将输出预测值的差异逐层反向传递,直到输入层。最终落在每个输入特征上的梯度累积,就是该特征的近似 Shapley 值。
GradientSHAP:积分梯度的期望化
GradientSHAP 结合了积分梯度(Integrated Gradients)与 SHAP 的博弈论公理,特别适合处理连续的 Embedding 向量空间。
数学本质:它假设特征是连续变化的。通过在背景分布和当前输入之间加入高斯噪声(Gaussian Noise)进行多次随机线性插值,并在这些插值点上计算模型输出相对于输入的梯度。
公式思想:特征的 SHAP 值被近似为其在插值路径上梯度的积分:
应用场景:当你需要解释高维的 Embedding 究竟捕获了什么信息,或者在平滑由于模型非线性产生的剧烈梯度波动时,GradientSHAP 是极其强大的理论武器。
SHAP 的工程指南
在真实的工业界应用中,SHAP 绝不仅仅是一个在模型训练结束后用来生成汇报图表的工具。它可以被嵌入前期的特征工程管道中,作为数据处理工具。
背景数据的压缩 (K-Means 近似)
在计算 KernelSHAP 或 DeepSHAP 时,公式中的边缘期望要求我们传入一个背景数据集。
陷阱:直接将数十万行的训练集作为背景数据传入
shap.DeepExplainer。这会使得模型在计算条件期望时,对每一个样本都要进行数十万次的前向推理,瞬间导致 Out Of Memory (OOM) 崩溃。工程解法:在代码层面,必须对背景数据进行降维压缩。标准的做法是使用 K-Means 聚类,将庞大的训练集浓缩成几十个具有代表性的质心(Centroids)。
这在保留数据整体边缘分布的同时,将计算复杂度降低了几个数量级,是 SHAP 在海量数据下可用的工程妥协。而这个背景数据本身又是我们研究对比精确解释的核心。
反哺大规模数据清洗
坚实的数据基础是后续进行模型微调或强化学习的生命线。SHAP 是极其高效的异常排查工具。
数据泄露 (Data Leakage) 侦测:
在 SHAP 概要图(Summary Plot)中,如果某个本应平平无奇的特征,其 SHAP 绝对值呈现出断崖式的领先,且完美地主导了分类结果。这通常意味着发生了数据泄露(例如,不小心把“最后登录时间”作为特征去预测“是否流失”)。
离群点 (Outliers) 与脏数据甄别:
在 SHAP 依赖图(Dependence Plot)中,正常的特征分布会形成清晰的非线性曲线或阶跃。如果在 X 轴的极端位置出现孤立的散点,且其 SHAP 效应(Y 轴)完全违背了业务常识,这强烈暗示该样本的特征在预处理或拼接阶段存在脏数据。此时必须立刻回到早期的大规模数据清洗逻辑中补充截断或过滤规则。
应对共线性的工程妥协 (Feature Grouping)
为了解决“特征相关性陷阱”,当必须把高度相关的特征(如多个维度的用户活跃度指标)喂给模型时,纯学术层面的不对称 Shapley 值计算成本太高。
工程解法:在解释阶段,不单独计算单个特征的 SHAP 值,而是将强共线性特征在代码层面打包成一个“特征联盟(Feature Group)”。只计算这个 Group 整体的 Shapley 值边界贡献。这样既防止重要性被错误平摊,又保证全局可加性的公理不被破坏。
参考资料
- Christoph Molnar, Interpretable Machine Learning: A Guide for Making Black Box Models Explainable, 3rd ed., 2025. 官方引用页
- Christoph Molnar, “SHAP” chapter, Interpretable Machine Learning. 章节链接
- Scott M. Lundberg and Su-In Lee, A Unified Approach to Interpreting Model Predictions, NeurIPS 2017. NeurIPS 页面
- Lloyd S. Shapley, A Value for n-Person Games, 1953.
- Title: Shapley and SHAP: State-of-the-Art Tools for Model Interpretability
- Author: Hyacehila
- Created at : 2026-02-27 16:00:00
- Updated at : 2026-07-01 23:56:19
- Link: https://hyacehila.github.io//blog/2026/02/28/shapley-and-shap/
- License: This work is licensed under CC BY-NC-SA 4.0.