Why I Am Not a Fan of R-Squared
本文核心观点翻译自 John Myles White 的文章 Why I’m Not a Fan of R-Squared
Take Home Message
不是单纯的模型误差函数,它的定义中还隐含了两个模型的比较:一个是当前被分析的模型,一个是所谓的常数模型(即只利用因变量均值进行预测的模型)。基于此, 回答的是这样一个问题:“我的模型是否比一个常数模型更好?”
但我们通常想要回答的是另一个完全不同的问题:
“我的模型是否比真实的模型更差?”
通过一些人为构造的例子可以发现,对这两个问题的回答不可互换。可以构造这样一个例子:我们的模型并不比常数模型好多少,同时也并不比真实的模型差多少。同样,也可以构造另一个例子,使我们的模型远比常数模型要好,却也远比真实模型要差。
与所有的模型比较方法一样, 不单是被比较模型的函数,它也是观测数据的函数。几乎对于所有的模型,都存在一个数据集,使得常数模型与真实模型之间是无法区分开的。具体来说,当使用一个模型区分效能很低的数据集时, 可以任意地向零趋近——即使我们对真实模型计算 也是如此。
因此,我们必须始终记住:
并不能告诉我们模型是否是对真实模型的一个良好近似, 只告诉我们,我们的模型在当前的数据下是否远比一个常数模型要好。
一个理论示例
为了理解“将模型与常数模型比较”如何导致与“将模型与真实模型比较”截然不同的结论,考虑一个简单的例子:我们想要对函数 进行建模,并在 个等间距点上观察到了带有噪声的数据。
首先,假设:
- 。
- 。
- 。
- 在 和 之间均匀分布的 1,000 个点上,我们观察到 ,其中 。
基于这些数据,我们尝试使用单变量 OLS 回归来学习 的模型,并拟合一个线性模型和一个二次模型。该建模过程的一个示例如下所示:
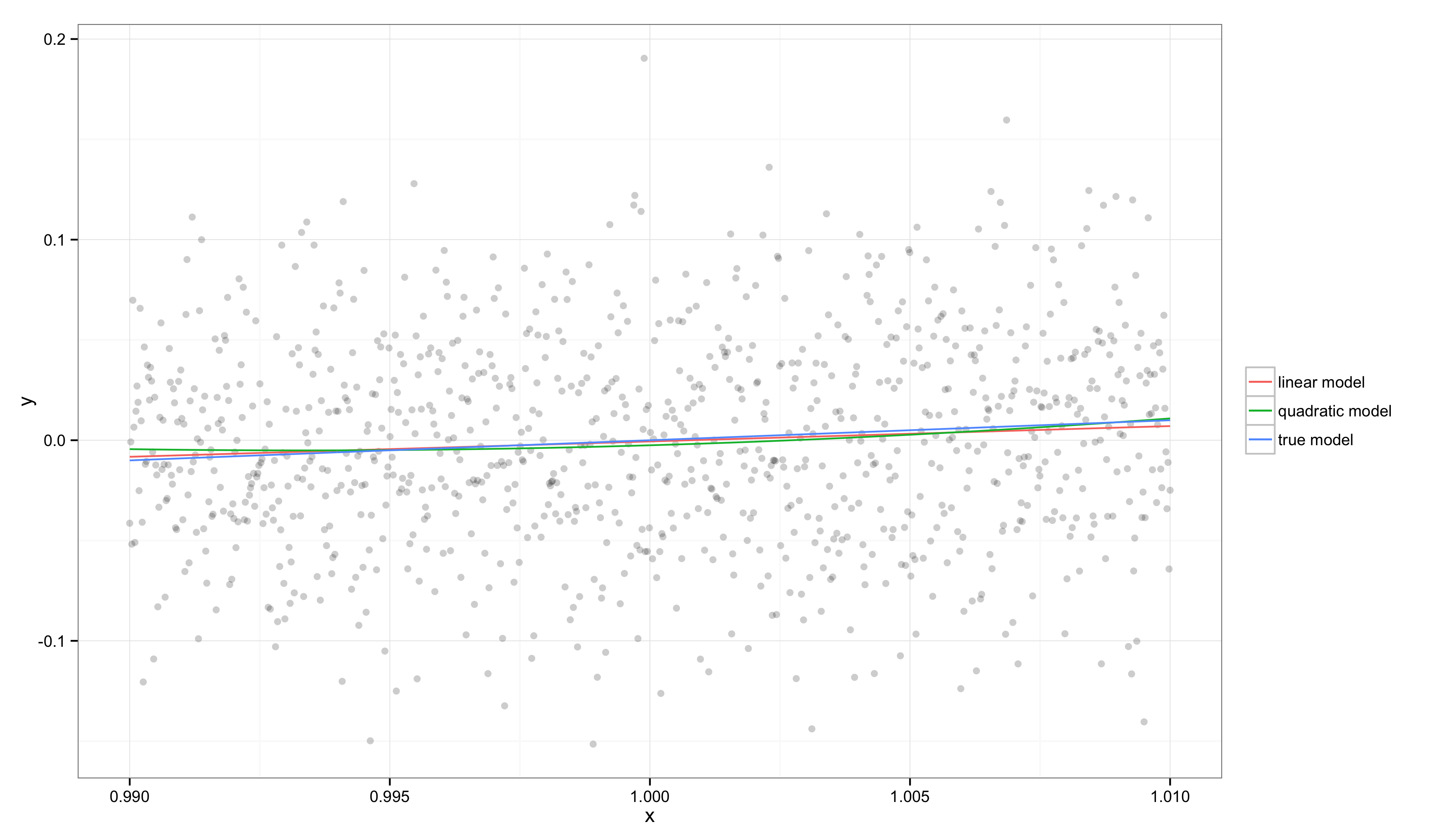
在这个图中, 可以很好地被一条直线近似,因此线性模型和二次回归模型都相当接近真实模型。这是因为 和 非常接近,在这一区域内,目标函数可以被线性近似,尤其是在考虑观测值噪声水平时。
如果计算这些模型的 ,会发现线性模型的 ,真实模型的 。这是一个很低的值,暗示我们的模型并不比常数模型好多少,尽管在这个局部范围内它已经是最好的线性近似。
很低的原因是,常数模型在此时已经是不错的模型;由于方差本身较大,模型很难拟合这样的噪声。
现在,如果 和 之间的差距变大,会发生什么?对于像 这样的单调函数, 会出现很奇怪的变化。
再看一个具体的例子,其中 且 :
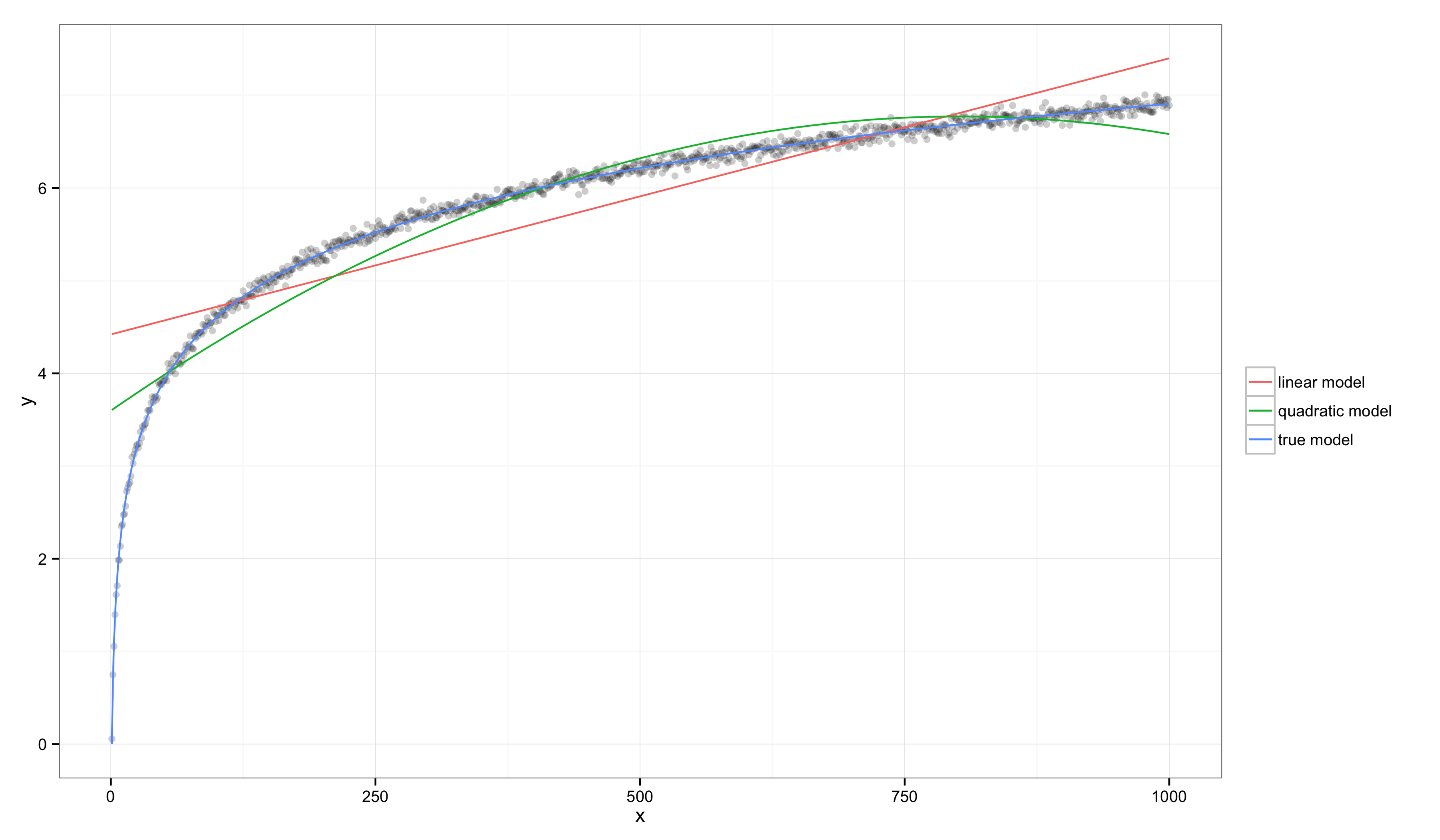
在这种情况下,通过视觉检查可以清楚地看到,线性模型和二次模型都存在系统性的不准确(因为对数函数显然不是线性的),但它们的 值却大幅上升了:线性模型的 ,真实模型的 。
这些例子表明,即使大多数人都会同意线性模型正在变成对真实模型越来越糟糕的近似(即系统性偏差越来越大),线性模型的 却可以大幅增加。这说明, 可能会产生误导。
结论
这些内容并不是让用户停止使用 ,但使用的前提是充分理解:
- 的值在很大程度上取决于所使用的数据集;
- 即使你的模型正在成为对真实模型越来越好的近似, 的值也可能会下降(反之亦然)。
在决定一个模型是否有用时,高的 未必可取,低的 也未必不可取。
这是一个无法回避的问题:一个错误(misspecified)的模型是否有用,总是取决于该模型应用的领域以及我们在该领域评估所有可能误差的方式。因为 包含了一个隐含的模型比较,它就受制于这种对数据集的普遍依赖性。
相比之下,像 MSE(均方误差)和 MAD(平均绝对偏差)这样的拟合度指标,其“缺陷”也是其优势所在。它们缺乏隐式归一化,表面上看是完全受领域影响的“任意数字”。这种特性反而迫使分析者正视指标对应用领域的敏感性——相比之下, 中的归一化使数字看起来不那么随意,也可能让人忘记模型评估对数据的依赖性,从而盲目认为高R方就一定好。
- Title: Why I Am Not a Fan of R-Squared
- Author: Hyacehila
- Created at : 2026-02-08 04:00:00
- Link: https://hyacehila.github.io//blog/2026/02/08/why-im-not-a-fan-of-r-squared/
- License: This work is licensed under CC BY-NC-SA 4.0.