Common Statistical Tests Are Linear Models
本文转载自 Jonas Kristoffer Lindeløv 的精彩文章 Common statistical tests are linear models 原文深入浅出地揭示了统计学中一个令人惊讶的简单真理:大多数常用的统计检验(t检验、相关分析、ANOVA、卡方检验等)都是线性模型的特例。
Common statistical tests are linear models
核心概念:万物皆线性
大多数常用的统计模型(t-test, correlation, ANOVA; chi-square, etc.)都是线性模型的特例,或者是近似的特例。我们不必死记硬背每一个检验的假设和公式,因为它们都可以归结为高中就学过的公式:
这种简单的美感降低了理解统计学的门槛。不论是频率学派、贝叶斯学派还是基于置换的推断,底层的线性模型都是一致的。
对于所谓的“非参数检验 (non-parametric tests)”,我们也可以用一种更直观的方式来理解:它们通常只是在秩变换 (rank-transformed) 数据上运行的对应参数检验。与其认为非参数检验“不需要假设”,不如将其理解为“在排名 (ranks) 上进行计算”。
下图概括了这一观点(点击查看PDF版本):
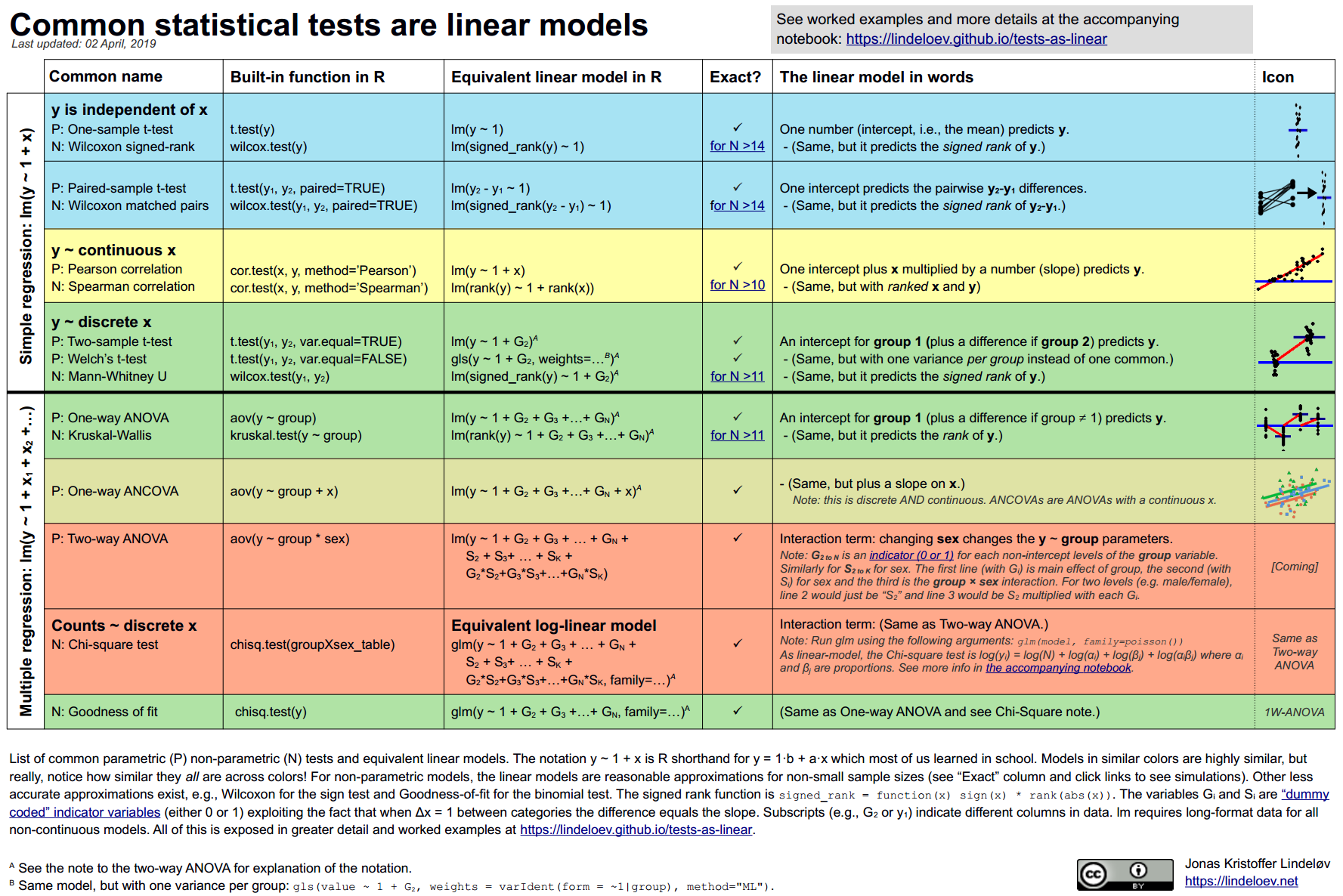
相关性 (Pearson and Spearman)
理论:作为线性模型
相关性分析的本质,就是寻找最佳拟合直线。模型公式如下:
这就是我们熟悉的 。在 R 语言中,我们通常写成 y ~ 1 + x,这代表 。不论怎么写,它都由截距 () 和斜率 () 构成。
秩变换 (Rank-transformation) 与 Spearman
Spearman 相关系数实际上就是对 和 进行秩变换 (Rank-transformation) 后的 Pearson 相关系数:
所谓“秩 (Rank)”,就是把数值替换为它们的大小排名(最小的为1,第二小为2…)。虽然 Spearman 的 p 值在小样本时只是近似值,但当 N > 10 时通常已经足够准确。
R 代码对照:Pearson
运行下面的 R 代码,你会发现线性模型 (lm) 产生的 , 值与内置的 cor.test 完全一致。
区别在于:lm 给出的是斜率,而 cor.test 给出的是相关系数 。如果我们将数据标准化(使 SD=1),那么斜率就等于 。
1 | # Built-in t-test |
R 代码对照:Spearman
同样的逻辑适用于 Spearman 相关,只需先对数据进行 rank() 变换:
1 | # Spearman correlation |
单均值 (One Mean)
理论:作为线性模型
单样本 T 检验 (One-sample t-test) 测试样本均值是否显著异于 0。这实际上是一个只有截距的线性模型:
这里没有 (或者说 ),所以剩下的 就是均值。
对于非参数对应的 Wilcoxon 符号秩检验 (Wilcoxon signed-rank test),原理相同,只是应用于符号秩 (signed ranks) 数据上:
R 代码对照:单样本 T 检验
1 | # Built-in t-test |
你会发现 lm(y ~ 1) 的输出中,截距项的估计值 (Estimate) 就是均值,t 值和 p 值也与 t.test 的结果完全一致。
R 代码对照:Wilcoxon 符号秩检验
1 | # Built-in |
使用 lm 不仅能得到匹配的 p 值,还能直接得到“平均符号秩”,这是一个比单纯的 W 统计量更直观的数字。
其他常用检验汇总
除了上述两个示例,其他常见的统计检验也都可以映射到线性模型中。为了保持本文简洁,以下列出摘要对照表,点击链接可查看原文详细推导和代码。
| 统计检验 (Test) | 线性模型公式 (Simulated LM) | 原文链接 |
|---|---|---|
| 双均值 (Two means) (Independent t-test) |
( 是二分类变量) |
Link |
| 方差分析 (Three or more means) (One-way ANOVA) |
(使用虚拟变量编码 Dummy coding) |
Link |
| 协方差分析 (ANCOVA) | Link | |
| 比例与卡方 (Proportions / Chi-square) | (Log-linear models,使用 Poisson 回归) |
Link |
总结
理解这些检验背后的线性模型关系,能让我们减少对特定“检验名称”的依赖,转而关注模型的构建。无论是 t 检验还是复杂的 ANOVA,它们都在回答同一个问题:我的模型参数是否显著不为零?
感谢 Jonas Kristoffer Lindeløv 提供的精彩视角。
- 原文链接: Common statistical tests are linear models
- Python 版本: Tests as linear (Python)
- GitHub 仓库: lindeloev/tests-as-linear
- Title: Common Statistical Tests Are Linear Models
- Author: Hyacehila
- Created at : 2026-02-07 04:00:00
- Link: https://hyacehila.github.io//blog/2026/02/07/common-statistical-tests-are-linear-models/
- License: This work is licensed under CC BY-NC-SA 4.0.