What Does the Loss Landscape of LLMs Look Like?
tldr:预训练不只是把模型推到某个最优点上,也会在参数空间里形成一片可容忍扰动的高维盆地。后续对齐、SFT 乃至越狱攻击,都可以放到这片地貌里理解。
如果你经常观察大模型的后训练现象,就会碰到一些看上去很矛盾的问题:模型明明已经很强了,为什么在一个看似正常的数据集上做完 SFT 之后,数学能力、推理能力或者安全能力会突然退化?为什么有时候只需要极少量对抗数据,模型就会像“失忆”一样把原本的能力丢得一干二净?又为什么在完全不改参数的前提下,仅靠 prompt 优化也能把模型引向危险输出?
这篇文章基于论文 Unveiling the Basin-Like Loss Landscape in Large Language Models,尝试用一个统一的几何视角来回答这些问题:把大模型看成行走在高维参数空间中的点,而模型能力则由这片空间的地貌决定。你会看到,问题不只是“有没有动参数”,还包括“沿着什么方向动了多远”。
另外,文末我补了一节额外讨论,引用并回应 Sun X 在 2026-03-10 发布的博客《关于大模型Loss Landscape的二次思考:博弈智能与通用智能的动力学深层原理》,进一步追问“公共谷底是否等于通用智能”、多任务为何会压缩搜索空间,以及这种思路如何延伸到多模态与 Agent。
现象:为什么模型会突然遗忘、越狱、能力塌缩
论文关注的是一个很具体的现象:alignment brittleness,也就是对齐后的脆弱性。它主要表现为三类问题:
- 正常微调后,模型的旧能力会意外受损,比如安全性掉了、数学能力忘了。
- 对抗微调只需要极少数据、极少 step,就能把模型推到完全不同的行为模式上。
- 输入空间里的 jailbreak,看起来像是另一类问题,但结果和参数攻击却惊人相似。
如果只从“数据质量好不好”或者“学习率是不是太大”去理解,这些现象当然能解释一部分,但解释不了全部。更进一步的问题是:为什么有些方向上的更新几乎不伤模型,而另一些方向上的更新却像悬崖一样陡?
Loss landscape 给出的视角是:模型不是在一个均匀空间里移动,而是在一片高度不均匀的地貌里移动。大多数方向也许都很平缓,可一旦撞上最坏方向,能力就会像从盆地边缘掉下去一样迅速塌缩。
Loss Landscape 怎么看:高维切片、随机方向与 benchmark
所谓 loss landscape,就是把“参数变化会如何影响模型表现”可视化。最基础的写法是:
其中 是当前模型参数, 是一个方向向量, 是沿这个方向移动的步长, 则是在数据集 上评估模型表现的 benchmark loss。
这里需要先说明一点:论文画出来的并不是训练时的 cross-entropy 曲面,而是基于生成结果的 benchmark loss。 作者会先把不同任务上的评测结果归一化到统一尺度,再画成一维切片。因此图里的纵轴更接近“能力是否被保住”,而不是“某个 token 的概率是否微调了一点点”。这也是为什么图里会出现一种很“字面意义上的盆地”形状:在一大段区间里,benchmark 几乎完全不变;一旦出界,性能会突然恶化。
在这个框架下,论文区分了两种最重要的 landscape:
- Most-case landscape:沿随机方向切开,观察“大多数方向”上的变化。
- Worst-case landscape:主动寻找最陡、最容易让模型失能的方向。
为什么随机挑一个方向就能说明问题?作者的经验发现是:对于足够大的 LLM,不同随机方向得到的曲线非常相似,于是单个随机切片可以近似代表“多数方向”的地貌。后面他们再用 Clopper-Pearson bound,把这种经验观察提升成统计上的方向比例下界。
不过这里有一个边界条件:这种 basin 结论依赖于生成式 benchmark。 如果你改用 log-likelihood 这类更连续的指标,landscape 往往会重新变得平滑。这里的盆地不是说“神经网络真实 loss 本身长得像一个方盒子”,而是说“从生成能力是否保持这个角度看,LLM 会呈现出明显的能力盆地”。
Most-Case Landscape:大模型为什么会长出 basin
先看论文里最重要的一张图。下面是 Qwen2.5-7B 在 most-case 方向上的 landscape,纵轴是归一化后的 benchmark loss,越接近 0 表示能力越完整:
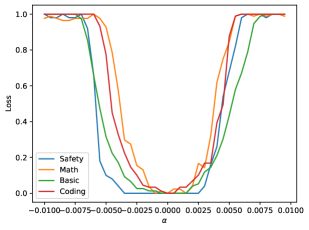
这张图基本概括了论文的主线。safety、math、basic、coding 四条曲线在中心区域都长时间贴近 0,说明模型在这一段参数扰动范围内几乎“不掉点”;可一旦继续往外走,loss 会迅速抬升到接近 1,意味着模型相关能力大幅退化。
这就是论文所说的 basin:不是传统小模型里那种光滑、圆润、处处都在连续变化的碗状曲面,而是一块很宽的稳定区。作者的直觉解释是,预训练已经把模型推进了一片足够大的高维稳定子空间,在这里做小范围移动,大多数 benchmark 都不会立刻坏掉。
另一个观察是,这种 basin 不是“从一开始就存在”,而是会随着模型规模增长逐渐出现。看 0.5B 的 Qwen:
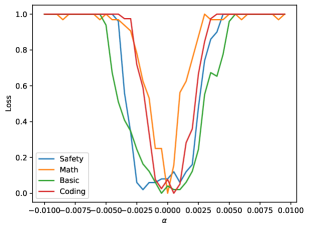
这张图更像我们熟悉的小模型 landscape:中心有低谷,但 plateau 很窄,四条曲线也更像连续收缩的 V 形谷地,而不是一片宽阔的稳定盆地。
再看 32B:
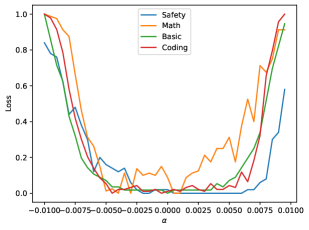
这时地貌就很不一样了。虽然它并不要求左右完全对称,但中间的低损区域明显变宽,模型可以在更大的参数邻域里维持原本能力。论文的核心观察之一就是:模型越大,basin 往往越明显、越宽。
这也解释了一个常见经验现象:大模型通常比小模型更“抗折腾”。这里的“抗折腾”不是说随便怎么调都没事,而是说在大多数随机方向上、在一定幅度内做更新,它不容易立刻牺牲已有能力。
Basic Basin 与 Capability Basin:预训练和对齐到底改了什么
如果顺着上面的图继续理解,论文给出了一个很有启发性的说法:预训练先创造 basic basin,后续对齐再在里面雕刻 capability basin。
所谓 basic basin,可以理解为模型最基础的语言理解、续写、对话能力所在的稳定区。模型一旦通过大规模预训练抵达这里,就具备了“像个语言模型一样工作”的最低能力。之后的指令对齐、安全对齐、数学微调、代码微调,并不是把模型传送到另一个完全无关的地方,而更像是在这片大盆地内部,把某些方向上的能力进一步塑形成更窄但更专门的子盆地。
这样一来,许多现象就顺理成章了:
- 如果某个能力对应的 basin 很大,那么模型在后续正常微调时更不容易忘掉它。
- 如果某个能力对应的 basin 很窄,那么稍微沿偏一点的方向更新,就可能把这项能力先撞坏。
- 不同模型家族的 basin 宽窄不同,所以同样的数据和超参数,在不同底座模型上会造成完全不同的副作用。
这也提醒我们,不要把 alignment 理解成“在预训练之上覆盖一层薄皮”。更贴切的说法是:对齐是在已有地貌里重新塑形。有的塑形非常充分,于是新能力的 basin 足够宽;有的塑形不够稳,于是一旦继续 SFT,就会先把这部分最脆弱的子结构抹掉。
Worst-Case 与 SFT-Case:为什么正常微调通常还好,对抗微调却能几步摧毁能力
如果只看 most-case,你会很容易得出一个过于乐观的结论:既然大多数方向都还挺安全,那为什么现实中还会出现“十条数据微调废一个模型”的事情?答案就在 worst-case direction。
先看 worst-case landscape:
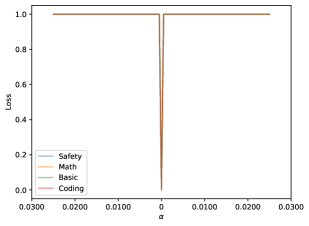
这张图几乎像一根针。除了极其狭窄的中心区域之外,四条能力曲线几乎瞬间就冲到高 loss。它传达的结论非常直接:虽然大多数方向都还不错,但参数空间里确实存在一些极端糟糕的方向,只要轻微偏移,模型就会迅速丢掉几乎全部能力。
这就给“少量对抗数据为何杀伤力极强”提供了几何解释。对抗微调不是在随机方向上慢慢走,而是在主动逼着模型朝最差方向走。它要做的不是累积大量更新量,而是尽快找到那个最容易破坏既有能力的出口。
论文进一步把 SFT 方向也画了出来。作者把它分成三种情形:benign、normal 和 adversarial。首版正文里我们保留前两种图,因为 adversarial 基本已经和 worst-case 重合。
先看 benign SFT,也就是和原始训练分布更接近、方向更温和的微调:
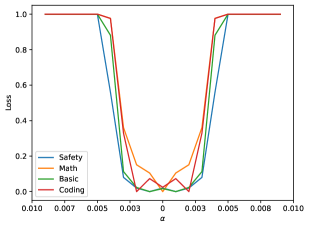
这条曲线仍然很像 most-case basin:中间稳定区足够宽,说明这类微调方向与原本的大盆地高度一致。论文里用的是官方的 Qwen2.5-7B-1M 版本来构造这个方向,直观上你可以把它理解为“继续沿着底座模型本来就熟悉的方向走”。
再看 normal SFT,也就是带有明显分布差异、但并非恶意数据的常规下游微调:
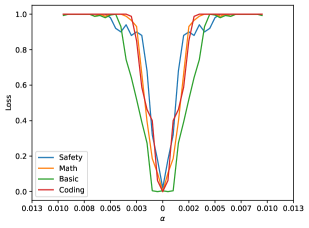
这时盆地明显变窄了。它还没有 worst-case 那么夸张,但已经不再像 benign SFT 那样宽松。这意味着:正常微调通常仍然处在“可控范围”内,但它的安全余量比 most-case 要小得多。 只要数据分布偏移更大、学习率更激进、训练步数更长,就更可能滑向能力退化。
所以,一个更准确的理解是:SFT 的方向并不是非黑即白地分成“安全”和“危险”,而是分布在一条连续谱上。越接近训练分布、越符合原模型地貌的微调方向,就越接近 most-case;越偏离原地貌、越被对抗目标牵引,就越接近 worst-case。
为什么 Prompt Attack 看起来像 Fine-Tune Attack
原文最后提出了一个问题:为什么不改参数、只优化输入,也能造成和微调类似的破坏?
从第一层激活来看,这两者的差别没有表面上那么大。设 embedding 矩阵是 ,输入是 。
如果我们扰动参数,第一层输出会变成:
如果我们扰动输入,第一层输出则变成:
于是问题就转化成:能不能找到一个输入扰动 ,使得
只要能做到这一点,两种攻击在第一层 activation space 里造成的效果就是一样的。论文引用的观点是:当前不少 LLM 的 embedding 层在列空间上足够“满”,于是这种等价在几何上是可实现的。也就是说,prompt optimization 可以被看作 parameter attack 在输入空间中的投影。
这当然不意味着“所有 jailbreak 都等价于一次微调”,但它解释了为什么两者经常表现出相似的脆弱性:它们都在想办法把模型推出原本稳定的 basin,只不过一个在参数空间里动手,另一个在输入空间里找等效扰动。
Basin 的理论意义:Clopper-Pearson、randomized smoothing 与能力下界
到这里,basin 还是一个经验观察。论文更进一步的地方在于:它试图把这个几何现象变成可度量、可证明的对象。
首先,作者定义了一个更“软”的 -basin。直觉上说,如果给模型参数加上标准差为 的高斯噪声,模型性能的期望几乎不变,那么就说明它拥有一个大小为 的 basin:
这个定义的好处是,它允许我们把“盆地大小”变成一个统计对象。接着就有两层理论意义。
第一层,是 Clopper-Pearson bound 给出的方向比例下界。
作者会在大量随机方向上测试:有多少方向在给定半径内仍然保持 benchmark 不变。由于这本质上是一个二项分布成功率估计问题,就可以用 Clopper-Pearson 给出严格的置信区间。于是“看起来大多数方向都安全”这句话,不再只是肉眼观图,而是可以写成“在置信水平 下,至少有 比例的方向满足 basin 条件”。
第二层,是 randomized smoothing 把 basin 大小转成了性能下界。
论文给出的直觉是:一旦对参数做高斯平滑,平滑后的 benchmark 相对于参数变化会变得更稳定。对应地,模型从 走到 后,性能下降可以被 basin 尺寸约束住:
不用死记这个公式,抓住结论就够了:同样的微调距离下, 越大,也就是 basin 越宽,性能下界就越好。
不过这里也要保持克制。论文自己也承认,理论保证的那片“certified region”通常比经验上观测到的 basin 小得多。换句话说,理论证书是保守下界,不是说“只要出了理论安全区,模型就一定坏掉”。现实中很多常规 SFT 仍然落在经验 basin 内,只是没有被强证书完全覆盖。
最后再强调一次边界条件:这里讨论的 basin 主要建立在生成式 benchmark 之上。如果换成 likelihood-based evaluation,loss landscape 往往又会重新变成平滑曲线。这不推翻 basin 视角,只是提醒我们——你看到的地貌,始终和你选择的评测方式有关。
Basin 能不能被主动做大:GO optimizer 的启发
如果 basin 大意味着“更不容易遗忘、更不容易被最坏方向击穿”,那自然会有一个后续问题:盆地能不能被主动做大?
论文给出的方向性答案是可以尝试。他们引入了一个 Gaussian-augmented Optimizer(GO optimizer),训练时不再只优化单点参数,而是优化参数邻域上的期望损失:
直觉上,它是在训练模型适应参数邻域里的小扰动,从而把单点最优,变成一片邻域都还不错的解。
下面这张图是 GPT2-127M 在 OpenWebText 上预训练后的 landscape 对比,红线是 GO,绿虚线是 AdamW:
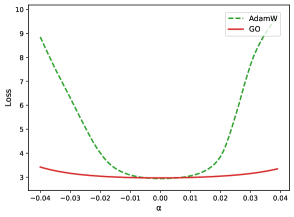
图里可以看到,GO 对应的曲线更平、更宽,说明它学到的不是一个尖锐的点,而是一块更稳定的区域。
这种更宽的 basin 在后续微调时也体现出收益。下面这张图比较了后续在 Alpaca 上继续训练后的表现:左轴是旧能力 OpenWebText 的 NLL,右轴是新能力 Alpaca 的 NLL。
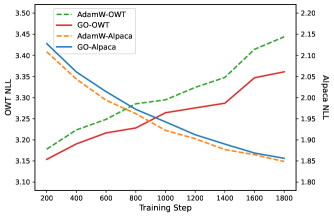
这里值得注意的不是绝对数值,而是趋势:GO 预训练出来的模型,在学新任务时并没有明显更慢,但旧能力掉得更少。这符合论文主线:如果预训练阶段就把 basin 做宽,后续 SFT 发生灾难性遗忘的概率就会更低。
当然,这一部分还远远不是工业结论。论文只在较小规模模型上做了验证,它更像一个明确的研究启发,而不是可以直接照搬到所有生产系统的 recipe。但它确实把“减少遗忘”这件事,从后训练技巧问题,重新拉回到了预训练几何结构问题。
把整篇文章收束成三句话,大概就是:
- 大模型的参数空间并不是均匀的,预训练会塑造出巨大的 basin。
- 对齐和常规微调通常是在 basin 内部塑形,而对抗数据会把模型牵向最坏方向。
- 如果想让模型更稳,重点不只是“少改一点参数”,还包括“能不能让模型周围那片可安全移动的空间更大”。
补充:从公共谷底到多任务动力学的二次思考
下面这节是额外补充。我主要引用并回应 Sun X 于 2026-03-10 发布的博客《关于大模型Loss Landscape的二次思考:博弈智能与通用智能的动力学深层原理》。以下内容主要是对该博客观点的转述与延伸,不代表原论文作者的直接主张;其中关于多任务动力学、Hessian 邻域体积和 data mixing 的讨论,更适合作为启发式理解,而不应当被当成原论文已经严格证明的结论。
公共谷底是否等于通用智能
这篇博客最有价值的一点,是它没有把“不同任务在相近参数点上共享谷底”直接等同于“模型已经找到了某种纯粹的通用智能内核”。博客作者对这种乐观解读非常警惕:如果公共谷底真的意味着存在一个可以脱离多任务训练而独立获得的“纯公共知识基底”,那么按这个逻辑,我们似乎只需要在少量任务上完成预训练,再把剩余任务留给后训练去激活即可。但现实并不是这样,表现好的大模型几乎都依赖大规模、异质、跨领域的数据混合预训练。
把这个怀疑和本文前面的 basin 叙事连起来,我更愿意把“公共谷底”理解成一种多任务约束下的稳定妥协区,而不是单一任务可外推一切的充分证据。原论文告诉我们,不同能力在相近区域里可以同时维持低 benchmark loss;但这最多说明模型在这片区域里找到了一组共享表征和稳健参数化,不足以推出“存在一套与多任务语料无关的纯公共知识”。
如果沿着这个视角继续往前走,那么预训练阶段为什么需要尽可能丰富、异构、广覆盖,也就更容易理解了:不是因为模型先拥有了一个纯粹的通用知识核,再去外插到别的任务;而是因为足够多的任务与数据分布同时参与塑形,才更可能形成那个稳定公共区域。
为什么多任务会减少搜索参数空间时的探索维度
博客的直觉是:多任务混合训练的重要作用,不只是让模型多学几门知识,还包括减少搜索参数空间时的探索维度。这个说法如果从过参数化模型的几何结构来看,其实非常自然。
对于一个高度过参数化的大模型,单任务训练通常对应的不只是一个最优点,而是一整片低损失流形。直观地说,模型有大量参数自由度可以互相补偿:你沿某些方向改动参数,任务 A 的 loss 几乎不变,于是优化器就能在这片很宽的平坦区域里“游荡”。从几何上看,这些方向就是单任务低损流形的切空间,也是模型搜索过程中最容易浪费掉的自由度。
一旦把任务 B、任务 C 再叠进来,情况就变了。每个任务都会定义自己的低损失流形,而多任务学习要找的是这些流形的交集。多个高维低损区域一旦求交,能同时保留下来的方向会明显减少;很多原本只对任务 A 无害的“自由滑动方向”,在任务 B 看来可能是陡峭上升方向,于是它们会被新的梯度信号直接抹掉。
所以我会把“减少探索维度”理解成:减少无效自由度,而不是把优化问题神奇地变成一个低维线性问题。 是从优化动力学的角度看,搜索不再发生在一个到处都能乱跑的巨大平原上,而更像进入一条更窄、更受约束的公共通道。
曲率、Hessian 与最优邻域体积的数学直觉
博客里最关键的数学直觉,来自把多任务总损失写成加权和:
如果在某个局部最优点 附近对单个任务做二阶近似,那么有:
这里的 就是第 个任务的 Hessian,它刻画了 loss 在各个方向上的局部曲率。于是,把多任务损失叠加起来之后,允许模型保持“误差不超过 ”的最优邻域,可以写成:
这个集合可以看成一个由总 Hessian 决定的超椭球。若记
其中 是正曲率子空间上的特征值,那么在主轴坐标里,上面的约束会变成
于是每条主轴的半径就是
也就是说,某个方向上的特征值越大,这个方向能容忍的参数扰动半径就越小。进一步地,在正曲率子空间里,这个超椭球的体积满足
这就是博客所说“多任务会压缩最优邻域体积”的数学直觉来源:当多个任务带来的 Hessian 近似独立、约束方向不完全重合时, 的有效特征值会被整体抬高,许多原本接近零的平坦方向会被额外约束激活。结果就是,满足同样误差容忍度的可行邻域会明显缩小。
当然,这里必须说清楚:这是一种理解博客猜想的数学直觉,不是本文主论文已经严格证明过的完整结论。现实训练里不仅有局部二阶近似失效的问题,还有非凸性、参数重标定不变性、不同任务 Hessian 不可交换等复杂因素。所以它更像一个帮助我们理解“为什么多任务会压缩无效自由度”的近似图景,而不是一条可以机械套用的定理。
多模态能否视为一种更强的多任务
我的判断是:可以,而且通常可以把它看成一种约束更强、异构性更高的多任务。 对于 VLM 或更一般的多模态模型,一个最简单的联合目标就可以写成:
其中既有文本建模损失,也有视觉建模损失,还有跨模态对齐损失。相比文本内多任务,这些约束的异构性要强得多:文本是离散符号结构,视觉是连续密集信号,而跨模态对齐又要求两者在共享语义空间里相互映射。
从 Hessian 视角看,多模态之所以可能约束更强,不只是因为“任务数更多”,而是因为不同模态对参数空间的剪裁方向更接近正交。某些在纯文本任务里几乎是零代价滑动的方向,到了视觉任务里可能会立刻变成高曲率方向;而某些视觉上的冗余方向,可能又会被语言对齐损失重新锁死。于是总 Hessian 的有效特征值更容易被整体抬高,原本的大量 null-space 和近零曲率方向会被削掉,满足同样误差阈值的最优邻域体积也就更可能继续收缩。
但这里我也想补上一句保守判断:邻域更小并不自动等于训练更容易。 多模态带来的不仅是更强约束,也是更大的优化不稳定、模态冲突和训练刚性。它确实可能更有利于逼出跨模态公共概念表征,但前提是损失配比、采样顺序、架构接口和对齐目标设置得足够合理,否则同样可能把模型拖进更难优化的状态。
异构反馈的价值,可能不仅在于给模型更多信息,也在于重塑 loss landscape,压缩策略空间里那些无效、投机、作弊式的探索通道。 如果这个判断大体成立,那么未来更好的 data mixing strategy,不一定只是“按知识覆盖率混数据”,也可能是“按几何塑形能力混数据”——也就是专门去设计哪些任务、哪些模态、哪些反馈应该同时出现,才能更有效地把模型推向既难以作弊、又具备迁移性的公共平坦谷底。
参考资料
- Title: What Does the Loss Landscape of LLMs Look Like?
- Author: Hyacehila
- Created at : 2026-02-22 12:00:00
- Link: https://hyacehila.github.io//blog/2026/02/22/loss-landscape-of-llms/
- License: This work is licensed under CC BY-NC-SA 4.0.